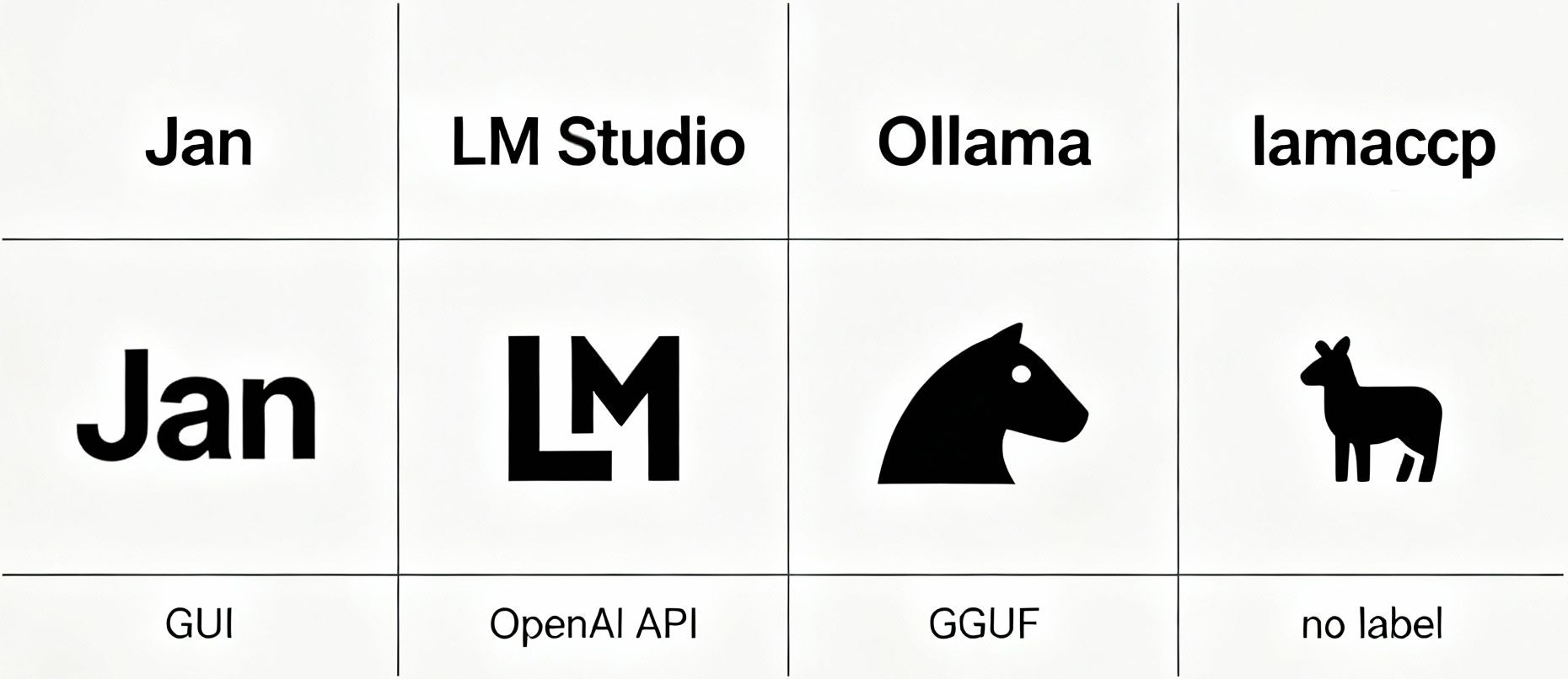
Running a GPT-style open model locally is now straightforward with tools like Ollama, Jan, LM Studio, and llama.cpp, letting models like GPT-OSS, Llama, and Mistral run fully offline with a local API or GUI.
What “local” really means
Local LLMs execute inference on-device, keeping prompts and outputs on disk or in RAM, avoiding third‑party servers and recurring API costs.
Modern wrappers provide simple CLIs and OpenAI‑compatible APIs so apps can swap between cloud and local backends with minimal code changes.
Quick picks by use case
Easiest 1‑click GUI: Jan or LM Studio; search/install “gpt-oss,” then chat offline.
Fast CLI + local API: Ollama; pull gpt-oss or other models and serve on localhost.
Fine control + bare‑metal speed: llama.cpp; run GGUF models with CPU/GPU acceleration.
Option A: Jan (5‑minute setup, beginner friendly)
Jan bundles a local chat UI and manages downloads/optimization automatically; install Jan, search “gpt‑oss,” download (~11 GB for 20B), then start chatting.
The 20B GPT‑OSS model runs fully offline with unlimited usage, suitable for general chat and coding help depending on hardware.
Option B: LM Studio (GUI with model hub)
Install LM Studio, download the GPT‑OSS model from its hub, and load it in the chat interface; works across Windows, macOS, and Linux.
LM Studio provides a polished UI plus local inference and supports multiple open‑weight families beyond GPT‑OSS.
Option C: Ollama (CLI + API)
Install Ollama, then pull a model, for example: gpt‑oss:20b or gpt‑oss:120b, and run it via command line or REST API.
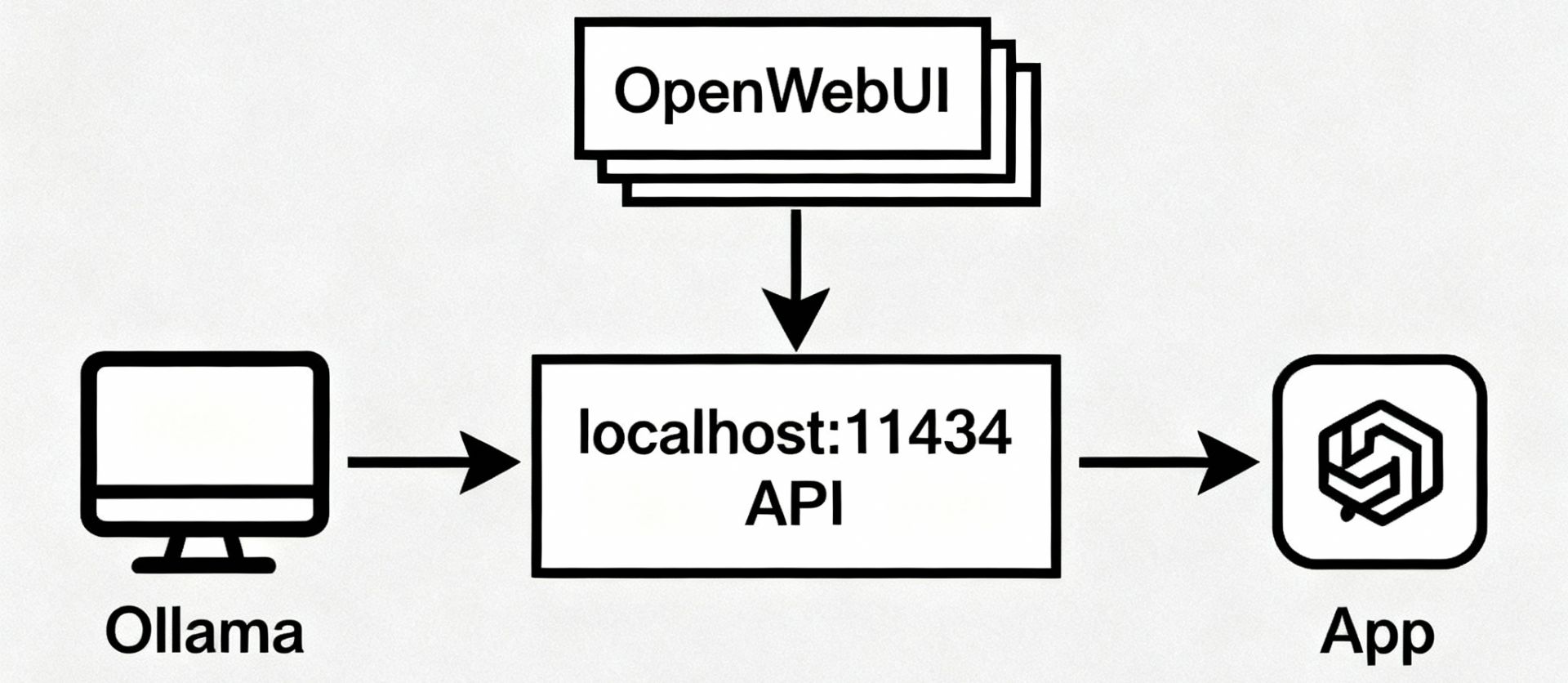
Ollama is favored for quick swaps between models, local endpoints, and pairing with OpenWebUI for a browser interface.
Sample Ollama workflow
Install Ollama for the OS, then pull the model: “ollama pull gpt-oss:20b” or “gpt-oss:120b”.
Run “ollama run gpt-oss:20b” to chat interactively or call the local API from apps.
Option D: llama.cpp (maximum control, GGUF format)
llama.cpp runs quantized GGUF models efficiently on CPU or GPU; it’s ideal for squeezing performance on modest hardware.
Typical flow: install llama.cpp bindings, download a compatible GGUF model, and run with CLI or Python for programmatic use.
Minimal llama.cpp Python setup
Create/activate an environment and install llama‑cpp‑python.
Download a compatible GGUF (e.g., a 7B/13B chat model) and load it via the binding for local inference.
Web UIs: Text Generation WebUI
Text Generation WebUI (oobabooga) offers a powerful browser UI and API, supporting loaders, presets, and extensions for power users.
Install via conda, pip requirements per hardware, then run server.py and browse to localhost:7860 to use models.
Hardware and sizing
Entry setups with 16 GB RAM can handle smaller or well‑quantized models; 32 GB+ RAM or a GPU with 6–12 GB VRAM improves speed and context.
7B–8B models run comfortably on midrange GPUs; 13B benefits from 16–24 GB VRAM or 4‑bit quantization; >30B often needs high‑VRAM or multi‑GPU.
GPT‑OSS specifics
GPT‑OSS includes open‑weight 20B and larger variants tuned for local use, installable via Jan, LM Studio, or Ollama.
Guides note rapid token speeds and offline usage, with model size dictating memory, storage, and throughput.
OpenAI‑compatible local APIs
Tools like Ollama expose endpoints that mimic OpenAI’s API patterns, easing drop‑in integration with existing apps and frameworks.
This enables routing requests locally for privacy or cost reasons and switching to cloud when needed.
Tips for better performance
Use quantized models (e.g., Q4_K_M) to fit in RAM/VRAM while keeping quality reasonable.
Pair Ollama with OpenWebUI for a friendly chat interface without changing the backend.
Troubleshooting and scaling up
If models fail to load, pick a smaller or more aggressively quantized build to match hardware limits.
For heavier workloads or experiments, host WebUI on a GPU cloud like RunPod with a suitable VRAM tier and then self‑connect.
Alternatives and ecosystem
Beyond GPT‑OSS, popular local families include Llama, Mistral, Gemma, and community distributions like GPT4All with a desktop app.
Codecademy and vendor guides provide copy‑paste steps for Ollama, Transformers, and LM Studio across Windows, macOS, and Linux.
TL;DR quick start
Fastest GUI: Install Jan, search and download “gpt‑oss‑20b,” start chatting locally.
Fastest API: Install Ollama, “ollama pull gpt‑oss:20b,” then run and call localhost.
Power user: Install llama.cpp, fetch a GGUF model, and run with CPU/GPU acceleration.


